

In this piece, we focused on low-level decisions in code that quietly increase cognitive load: things like poor naming, deep nesting, magic values, etc. These choices often go unnoticed in the moment, but their impact adds up — making code harder to understand, maintain, and extend over time.
When we think about complexity in software systems, our minds often jump to architecture diagrams, distributed systems, or multi-threaded concurrency nightmares. But in reality, complexity usually creeps in quietly, through small, seemingly insignificant choices: a deeply nested condition, a vague function name, a misused abstraction. It can lead to the death by a thousand paper cuts — no single decision sinks the system, but the accumulation wears it down, slows progress, and makes change harder than it should be.
Poor Naming
Naming is one of the most powerful tools we have as developers — and one of the easiest to misuse. When names are vague, overly generic, or misleading, they turn code into a puzzle. A variable called data, a function called handle(), or a class named Manager tells us almost nothing about what these things do or are. In mobile development, it’s common to stumble upon things like InfoView, HelperClass, or process() — labels that beg the question: what info? which helper? process what?
Poor naming forces readers to dig for context, scanning other parts of the code to figure out what something means. It increases the time it takes to understand the logic and decreases confidence when making changes. Worse, it creates a false sense of understanding — a name like updateUI() might sound harmless until you realize it’s triggering network calls and state changes under the hood.
Good names reveal intent. A function called fetchUserProfile() or a type called OnboardingStepViewModel communicates its purpose directly, without requiring comments or detective work. When names obscure the real purpose or behavior of code, it becomes harder to reason about the system as a whole. Understanding what each piece does, how it fits with others, or where responsibility lies becomes a constant cognitive burden. Over time, the system becomes fragile not because it’s technically flawed, but because it’s semantically incoherent. Clear, purposeful naming is the first step toward a codebase that’s easy to read, maintain, and grow.
Cyclomatic complexity
High cyclomatic complexity is often a sign that a function is trying to do too much. It means the number of distinct paths through the code is high — often due to excessive branching with if, switch, guard, or complex nesting of conditions. While technically it might still “work,” reading it feels like navigating a maze. You can’t simply follow the logic top to bottom; instead, your mind has to simulate conditions, jump between branches, and keep a mental stack of possible outcomes.
A high-complexity function resists change because each small edit might ripple through a dozen logic paths. Bugs hide in obscure branches. Unit tests become hard to write or incomplete. The solution is not to avoid branching altogether, but to isolate it. Break down decision logic into smaller, testable functions. Favor early returns and reduce deep nesting. Refactor complex conditionals into named booleans or even strategy objects. The goal isn’t to chase a number — it’s to shape the code so that reasoning about it becomes linear again.
More complex:
func doSomething(x: Int) -> Int {
let y = x + 10
if y > 0 {
return y
} else {
return 0
}
}
Less complex:
func doSomething(x: Int) -> Int {
let y = x + 10
return y
}
Sometimes this complexity is essential (inherent to the problem), so we cannot do much with it. The 2 funtions in the previous example just do different things.
But in other cases we can do some changes to minimise cyclomatic complexity.
More complex:
func handleNotification(_ type: String, isUserLoggedIn: Bool) {
if type == "message" {
if isUserLoggedIn {
openMessages()
} else {
showLoginPrompt()
}
} else if type == "promo" {
showPromotion()
} else if type == "alert" {
showAlert()
}
}
(cyclomatic complexity = 5)
Less complex:
func handleNotification(_ type: String, isUserLoggedIn: Bool) {
switch type {
case "message":
handleMessage(isUserLoggedIn)
case "promo":
showPromotion()
case "alert":
showAlert()
default:
break
}
}
func handleMessage(_ isUserLoggedIn: Bool) {
isUserLoggedIn ? openMessages() : showLoginPrompt()
}
(cyclomatic complexity = 3 + 2)
Even though the overall complexity of this piece of logic remained the same we split it into 2 functions and made it more digestable. As in most cases you don’t need to consume it all at once. Moreover we got a better separation of concerns; and 2 small functions are easier to test then one big one.
It’s usually considered that when a function has more than two or three returns, it’s a sign that the complexity is too high and refactoring is suggested. With complexity more than 10, a linter normally shows a red flag.
Nesting level
Nesting level is something we can fully control as developers. In the following example we have 3 levels of nested types: PaymentConfiguration, Entry, and Content.
public struct PaymentConfiguration {
public struct Entry {
public enum Content {
case modal(PaymentContext)
case deepLink(DeepLinkContext)
}
public let title: String
public let content: Content
public init(title: String,
content: Content) {
self.title = title
self.content = content
}
}
public let entries: [Entry]
public init(entries: [Entry]) {
self.entries = entries
}
}
The cognitive load of such solution high as for each nested structure you need to keep the context of its parent (or even grandparent) in mind. You deal with the Content, but you will likely need to consider Entry and maybe even PaymentConfiguration for the full context. The cognitive contexts of them overlap:
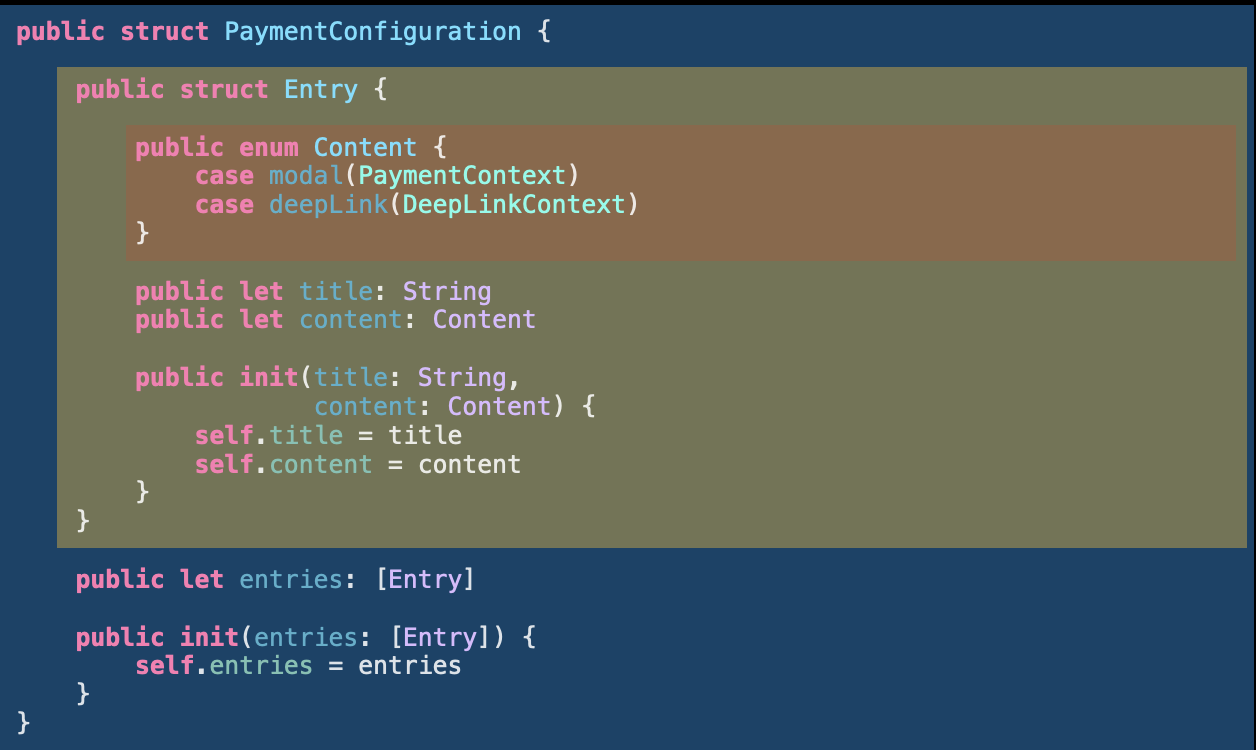
So in this case it’s probably easier to split them into a separate data types, even if it looks more verbose in terms of naming.
public struct PaymentConfiguration {
public let entries: [PaymentConfigurationEntry]
public init(entries: [PaymentConfigurationEntry]) {
self.entries = entries
}
}
public struct PaymentConfigurationEntry {
public let title: String
public let content: PaymentConfigurationEntryEntryContent
public init(title: String,
content: Content) {
self.title = title
self.content = content
}
}
public enum PaymentConfigurationEntryEntryContent {
case modal(PaymentContext)
case confirmedDeepLink(DeepLinkContext)
}
This way the contexts don’t overlap:
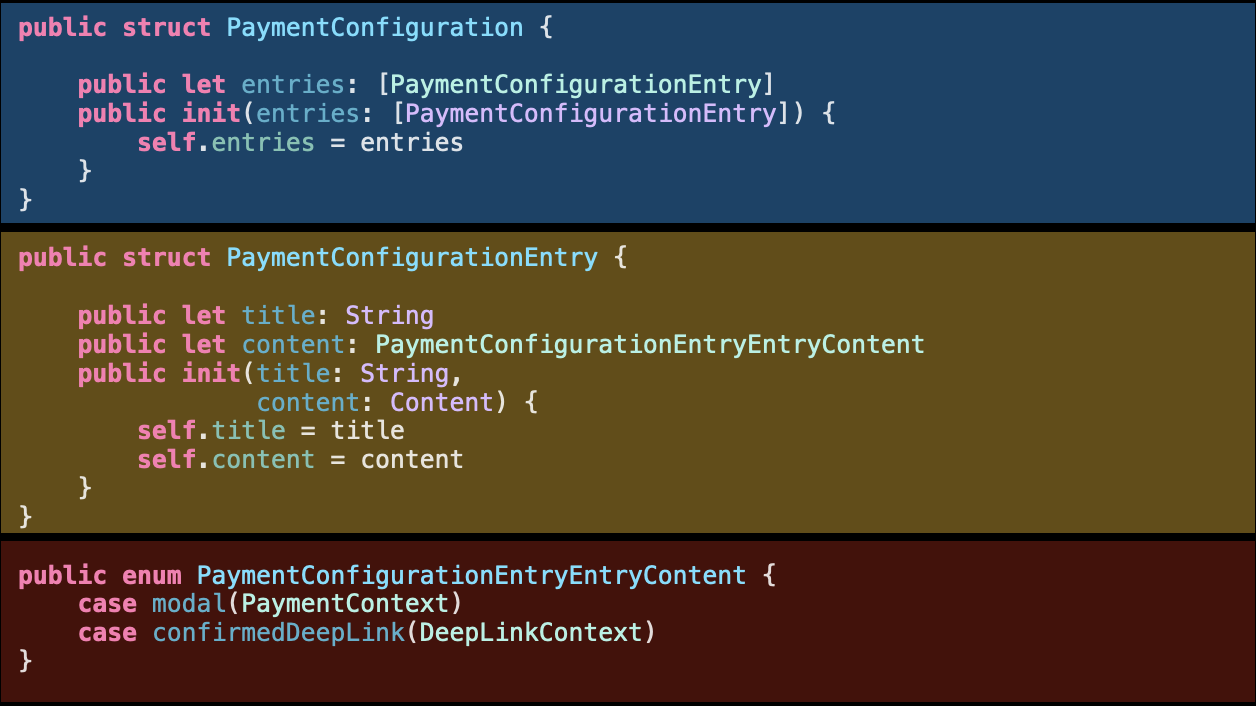
There might be some exception like using nested structs and enums as name spaces.
public enum AccessibilityIdentifiers {
// MARK: - AboutThisApp
public enum About {
public static var view = "view"
public static var list = "list"
public static var tour = "tour"
public enum Legal {
public static var view = "view"
public static var terms = "legal"
public static var copyrights = "copyrights"
public enum Copyrights {
public static var view = "view"
...
}
...
}
...
}
}
So it can be used like AccessibilityIdentifiers.About.Legal.copyrights.
But be careful with it, it only works when you don’t need to get inside this nested types, which is the case for constants like Accessibility Identifiers. If the types require instantiation or even some logic (like the previous example with AboutThisAppConfiguration), you will need to ocasionally take a look inside it. Hence no nesting is suggested in those cases.
Number of parameters
Functions with too many parameters often signal a deeper design issue. They might be taking on multiple responsibilities, or they’re being forced to know too much about their environment. From a cognitive standpoint, each parameter is a fact the reader must keep in mind while understanding the function. As the number grows, it becomes harder to mentally simulate the behavior, trace data flow, or confidently make changes.
One way to address this is by grouping related parameters into meaningful data structures — for example, bundling latitude, longitude, and altitude into a Location object, or firstName, lastName, and email into a UserProfile. This not only simplifies the function signature, but also communicates the conceptual relationship between the parameters.
More complex:
public func trackEvent(formId: String,
formStep: String,
formStatus: String,
transactionId: String?,
formOutcome: String?,
formType: String?) {
...
}
Less complex:
public func trackEvent(content: EventContent) {
...
}
public struct EventContent: Equatable, Sendable {
public let formId: String
public let formStep: String
public let formStatus: String
public let transactionId: String?
public let formOutcome: String?
public let formType: String?
}
This reduces the number of entities you need to keep in mind when working with the function.
In other cases, if a function is doing too much and therefore needs too much context, it might be time to split it into smaller, more focused pieces. Reducing parameter count improves readability, testability, and long-term maintainability.
Complex conditions
Complex conditions may be completely unreadable:
if (yourFeatureToggleState == .enabled &&
(numberOfLaunches >= configuration.minimumRequiredLaunches) ||
(currentDate >= nextPromptDate &&
applicationVersion != latestVersionWithAlert)) {
attemptToShowAlert(in: window, completion: completion)
}
A better approach: break them into logical steps, assign parts to descriptive boolean variables, use those variables to make the condition self-explanatory:
let featureIsActive = yourFeatureToggleState == .enabled
let enoughLaunches = numberOfLaunches >= configuration.minimumRequiredLaunches
let dateVersionConditionMet = (currentDate >= nextPromptDate &&
applicationVersion != latestVersionWithAlert)
if featureIsActive && (enoughLaunches || dateVersionConditionMet) {
attemptToShowNativeRating(in: windowScene, completion: completion)
}
Nested if
Nested if-conditions (which are a specific case of increasing cyclomatic complexity) deserve a separate mention, as it’s one of the most widely spread anti-pattern. Usually you can quite easily simplify it:
More complex:
if cardIds.count > 1 {
cardDismissHandler()
} else {
if viewController != nil {
cardDismissHandler()
}
delegate?.dismissViewController(at: location)
}
Less complex:
if cardIds.count > 1 || viewController != nil {
cardDismissHandler()
} else {
delegate?.dismissViewController(at: location)
}
If your language supports early returns or constructs like guard, you can flatten the structure and improve readability:
More complex:
if let cardId {
if let element = interaction.element(for: location,
cardId: cardId) else {
return
}
} else {
tracker.trackElements(element,
page: analyticsPage(with: productName))
}
Less complex:
guard let cardId, let element = interaction.element(for: insightsLocation,
cardId: cardId) else {
return
}
tracker.trackElements(element, page: analyticsPage(with: productName))
Magic Numbers and Strings
Magic numbers and strings refer to hardcoded values that are used directly in the code without any explanation of their meaning or purpose. These “magic” values can significantly increase cognitive load, as developers must either infer their purpose from context or search through the codebase to understand what they represent. This makes the code harder to maintain and extend because any changes to these values require updating them in multiple places, increasing the risk of errors. Using descriptive constants instead of magic numbers or strings makes the code more readable and maintainable, as the intent behind the values is clearer and any future changes can be made in one central location.
More complex:
func calculateDiscount(price: Double) -> Double {
if price > 100.0 {
return price * 0.1
}
return price * 0.05
}
In the above example, 100.0 and 0.1 are magic numbers. It’s unclear why 100 is the threshold for a discount or what the significance of 0.1 is.
Less complex:
let DISCOUNT_THRESHOLD: Double = 100.0
let STANDARD_DISCOUNT_RATE: Double = 0.05
let PREMIUM_DISCOUNT_RATE: Double = 0.1
func calculateDiscount(price: Double) -> Double {
if price > DISCOUNT_THRESHOLD {
return price * PREMIUM_DISCOUNT_RATE
}
return price * STANDARD_DISCOUNT_RATE
}
By using constants with descriptive names, the intent of the values becomes much clearer, reducing complexity and making the code easier to understand and maintain.
Implicit Context or Hidden State
Code that relies on implicit context — such as global variables, singleton instances, or shared mutable state — quickly becomes difficult to reason about. When a function depends on or mutates state that isn’t passed in explicitly, it creates invisible dependencies. From the outside, it’s unclear what the function needs to operate correctly or how it might change the state of the system. This makes the code fragile: changing one piece can unintentionally break another, and understanding a function in isolation becomes almost impossible.
This kind of hidden complexity increases cognitive load because it forces developers to mentally reconstruct the larger system state just to understand a small piece of behavior. For example, a UserSessionManager that reads the current user from a global AuthContext may seem convenient, but any changes to the context mechanism or its timing can have unpredictable ripple effects. A better approach is to pass the necessary data explicitly and return any results or changes transparently. This not only makes individual components easier to understand and test, but also encourages better separation of concerns and modular design.
Summary: The Accumulated Weight of Small Decisions
In this section, we explored how seemingly small, low-level decisions in code can significantly increase the cognitive load on developers. These patterns don’t usually break a system outright, but they do make the code harder to read, reason about, and modify. The more of them you allow to creep in, the more they compound, gradually turning simple features into fragile puzzles.
This additive nature of complexity is what makes these small decisions matter. While any one of them might seem harmless, their combined effect is felt most painfully during maintenance or when new features need to be added. Codebases don’t become hard to work with overnight — they erode slowly, one decision at a time.
And this is just the surface. Classic books like Clean Code (Robert C. Martin), Code Complete (Steve McConnell), and Refactoring (Martin Fowler) dedicate entire chapters to these and many other micro-decisions that influence clarity, maintainability, and quality. They’re excellent resources if you want to dive deeper into best practices and learn how to spot and improve problematic code patterns.
As a guiding principle, always remember: code is written for humans first, and machines second. Compilers are fine with cryptic, tangled code — your teammates (and your future self) are not. Writing clean, understandable code is an investment in long-term productivity and peace of mind.