

How we distribute logic and structure code across a project plays a major role in how complex that project feels. Even well-written code can become hard to work with if it’s scattered, inconsistently organized, or buried in the wrong place.
Developers spend a large portion of their time reading, navigating, and understanding code — not writing it — so clear structure is essential. A thoughtful distribution of logic reduces the mental effort required to follow the flow of the app, understand responsibilities, and make safe changes. In short, good structure keeps cognitive load low and complexity in check.
Foundational Principles
Clear structure helps reduce complexity — but knowing how to separate and organize code well is not always obvious. As projects grow, responsibilities blur, logic spreads, and it becomes harder to decide where things should live. Fortunately, there are a few foundational principles that serve as practical guidelines for distributing logic in ways that reduce cognitive load and improve maintainability. These principles can be grouped into three categories, each addressing a different aspect of structure: limiting responsibilities, deciding what belongs together or apart, and controlling how much code knows about other code. Together, they help us shape systems where each part is easier to understand, reason about, and evolve — the very qualities that keep complexity under control.
1. Limiting Responsibilities: What should this code be responsible for?
Separation of Concerns (SoC) is about dividing the system into parts that focus on different areas — such as UI rendering, business logic, networking, or persistence. When different responsibilities are mixed together — for instance, a view controller that fetches data, parses it, formats it for display, updates the UI, and manages navigation — the result is code that’s harder to reason about, harder to change, and more error-prone. SoC helps reduce complexity by ensuring each part of the system has a clear and focused role.
The Single Responsibility Principle (SRP) takes this idea to a more granular level, guiding how we design individual types and functions. Each class or function should have one reason to change. This helps isolate concerns and reduces the risk of unintended side effects during refactoring.
In practice, we apply these principles at multiple levels of abstraction:
-
At the app level, we separate responsibilities across feature modules or sections of the app. For example, the onboarding flow, user profile, and checkout process might each live in their own isolated modules with clear ownership and dedicated navigation flows.
- At the functional layer, we move responsibilities into dedicated roles, for example:
- View controllers to handle UI rendering and user interaction.
- View models - to manage presentation logic and data preparation.
- Coordinators (or flow controllers) - to control navigation and screen transitions.
- Services - to handle specific tasks like networking, analytics, persistence, or remote configuration.
- At the function and data type level, we apply SRP by avoiding bloated types and breaking down logic into focused pieces:
- A function that parses and validates input might delegate formatting to a separate utility.
- A data model might be accompanied by a display model that formats its data for presentation.
- An API client should only concern itself with networking — not with how the data will be shown or stored.
These decisions aren’t always black and white. There’s a trade-off between separating responsibilities and over-fragmenting the codebase. If separation is taken too far, you may end up with many tiny components that are hard to trace and understand in context — increasing rather than reducing cognitive load. The key is clarity: split responsibilities when doing so makes the system easier to understand, test, and evolve — not just to follow a rule. Thoughtful separation leads to a codebase where each part does one thing well and is easy to reason about in isolation.
2. What Belongs Together: Which pieces of logic should be grouped, and which should be separated?
When making decisions about grouping or separating logic — whether it’s functions, data types, functional layers, or entire feature modules — a few helpful questions can guide you:
- Do you mostly need to keep the parts together in mind?
- Are the parts normally used together?
- Is it hard to understand one without the other?
- Do they have shared state, dependency, or data model?
- Do they manipulate the same object or concept?
- Do they perform different operations?
- Do they have different levels of detail or abstraction?
- Do they have a semantic relationship (e.g., general vs. specialized behavior)?
While responsibility defines what a piece of code should do, cohesion and coupling help us decide how things should be grouped and how they should interact. These principles are essential in shaping systems that are easy to navigate and evolve — they reduce the number of concepts a developer must juggle when working within a codebase.
Cohesion refers to how closely related the functions and data within a module, type, or file are. High cohesion means everything inside serves a common purpose — making the module easier to understand and reason about. Low cohesion, by contrast, is a red flag: it suggests that unrelated logic has been lumped together, often out of convenience. For example, a UserManager that handles user authentication, profile formatting, local caching, and UI updates is trying to do too much. Splitting these into more focused units — like an AuthService, UserProfileFormatter, or CacheManager — improves clarity and testability.
Coupling measures how dependent one piece of code is on another. Tight coupling means that changes in one component may require changes in another, which makes the system brittle and harder to maintain. Loose coupling enables components to evolve independently. For instance, if your view model is directly instantiating and managing its dependencies (e.g., networking code, data models), it becomes tightly coupled to them. Introducing abstractions like protocols and dependency injection reduces that coupling, allowing different parts of the codebase to be reused, tested, and replaced in isolation.
You can see these principles applied at multiple levels:
-
In feature modules: Grouping all the files related to a single feature — its views, view models, services, and navigation logic — into one place increases cohesion. This minimizes the mental jumps needed to understand or change a feature.
-
In types: A model object should only contain logic relevant to its role. Avoid putting formatting, validation, and networking logic into a single struct or class.
-
In functions: A function that handles user input should not also log analytics or trigger navigation. Keeping related behavior together, and unrelated behavior separate, leads to smaller, more focused functions that are easier to understand and reuse.
High cohesion and low coupling work together to reduce cognitive load. They localize logic, clarify intent, and limit the surface area affected by change — all of which make a codebase feel more navigable and less overwhelming.
3. Limiting Knowledge: How much should one part of the system know about another?
The third group of principles focuses on visibility and dependencies — in other words, how much knowledge one part of the system has about another. The less a component needs to know about the internals of others, the easier it is to understand and change in isolation. This group includes encapsulation, information hiding, and the Law of Demeter.
Encapsulation is about hiding internal implementation details behind well-defined interfaces. When we encapsulate properly, other parts of the system don’t rely on the internal mechanics of a component — only on its public contract. This allows us to refactor the internal workings without breaking everything that depends on it. For instance, a DataStore might expose simple methods like save() and load() while hiding how the data is serialized or where it’s stored.
Information hiding extends this idea to a broader scale. It’s the principle of not exposing more than what’s needed. A module shouldn’t leak internal types, intermediate states, or implementation-specific details unless absolutely necessary. This keeps boundaries clean and reduces the chance of other components forming hidden dependencies.
The Law of Demeter (“don’t talk to strangers”) advises that code should only interact with objects it directly owns or receives. This prevents “train wreck” code like user.profile.settings.theme.name, which exposes deep internal structures and creates tight coupling. Instead, higher-level objects should expose what’s needed explicitly. For example, user.displayThemeName is much easier to consume and hides the internal structure of the user profile.
These principles help reduce complexity by minimizing the amount of knowledge a developer needs to understand or safely modify a piece of code. When modules and types act as black boxes with clear inputs and outputs, it becomes easier to reason about behavior, write tests, and change internals without fear of unintended consequences.
Applying the Principles in Practice: Modularisation
Splitting an application into multiple modules or components is one of the most effective ways to reduce complexity in larger projects. By breaking the system into logical units — such as Authentication, Payments, UserProfile, or DesignSystem — we create bounded contexts that are easier to understand, maintain, and evolve independently.
This practice directly applies principles like separation of concerns (each module handles its own domain), single responsibility (modules have one clear purpose), encapsulation (internal details are hidden behind module interfaces), and low coupling (modules depend only on well-defined contracts, not each other’s internals).
A well-modularized project allows teams to work in parallel, isolate bugs, write better-targeted tests, and reduce the mental overhead of navigating a massive codebase. Developers can reason about a feature in isolation, without needing to understand unrelated parts of the system. It also enables more controlled dependencies — for example, UI might depend on DesignSystem, but DesignSystem never depends on UI, keeping the dependency graph clean and directional.
Modularization doesn’t just reduce build times or improve testability — it helps shape the architecture in a way that reflects the real structure of the domain. This alignment lowers complexity and boosts confidence in the codebase. Also by applying decomposition we split one piece (an app or a feature module) into smaller and more digestable pieces.
Applying the Principles in Practice: Project structure
The way we organize files and folders in a project is a direct reflection of the principles we’ve covered: separation of concerns, single responsibility, cohesion, coupling, and encapsulation. A thoughtful physical structure supports these ideas and helps reduce complexity by making the system easier to navigate and understand.
A common choice is between layer-based and feature-based structures. Layer-based organization groups files by type — for example, all views in one folder, all services in another. While this can work in simple projects, it often forces developers to jump across the codebase to trace a single feature. A feature-based structure, on the other hand, keeps related logic together — such as placing ProfileView.swift, ProfileViewModel.swift, and ProfileService.swift within a Profile/ module. This approach increases cohesion and reduces the mental effort required to understand and modify a feature.
In Swift, it’s also important to be mindful of how we use extensions. It’s common to break a type into multiple files using extensions — for example: User.swift defines the core model, User+Decoding.swift adds conformance to Decodable, and User+Display.swift contains UI formatting logic. While this can improve clarity when used carefully, excessive fragmentation leads to poor cohesion and makes it harder to form a complete mental model of the type.
Files like Utils.swift, Helpers.swift, or Extensions.swift are another frequent sign of structural issues. These vaguely named containers often become dumping grounds for unrelated logic, violating principles like single responsibility and information hiding.
Ultimately, good physical structure aligns with how we think about the system. It helps developers find what they need, understand the scope of changes, and maintain the codebase with confidence.
Applying the Principles in Practice: Refactoring a function
Here is the function that is triggered when a deep link arrives to the app. It’s quite verbose, so don’t dig into its details now.
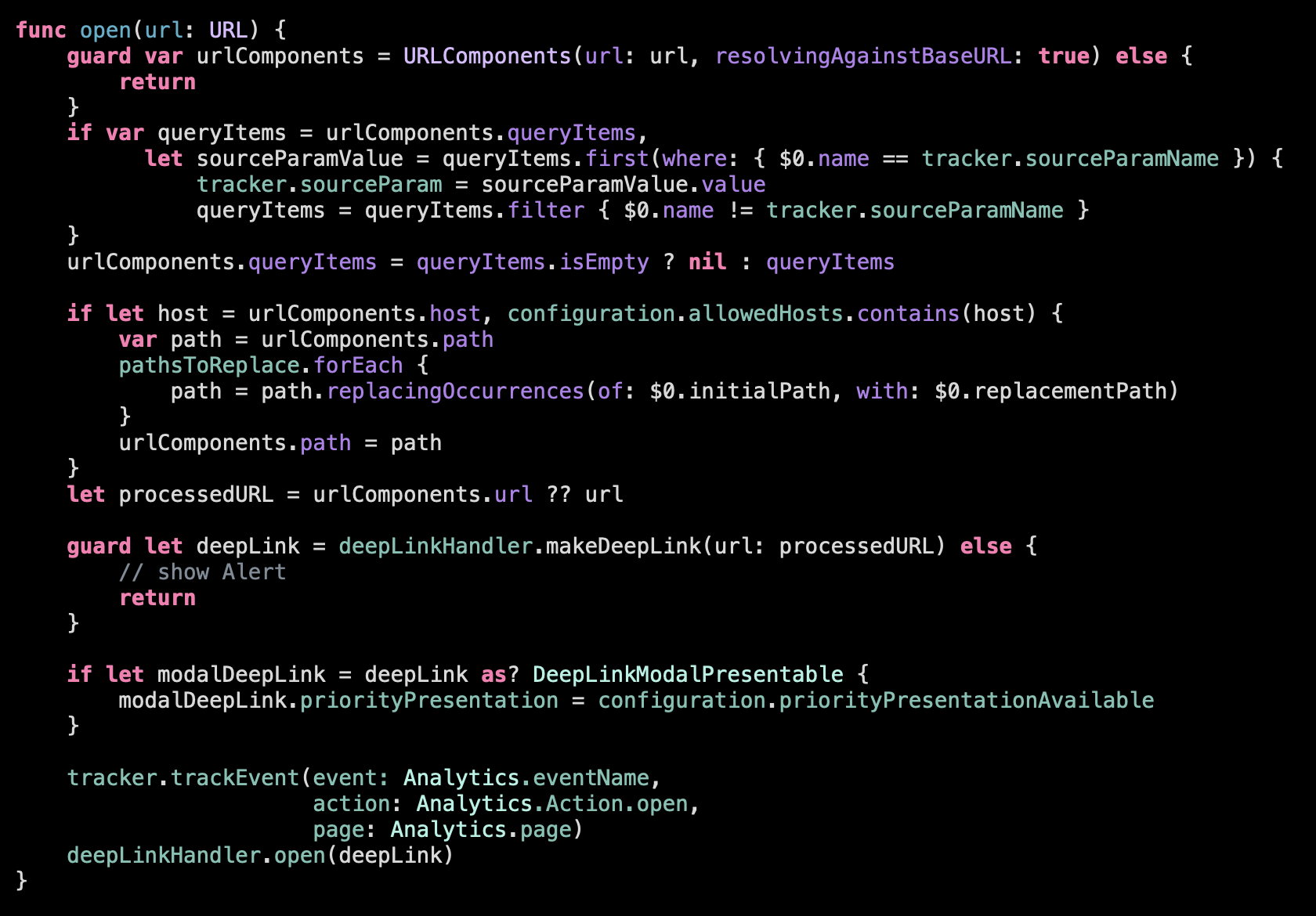
Let’s see what the function does on a high level:
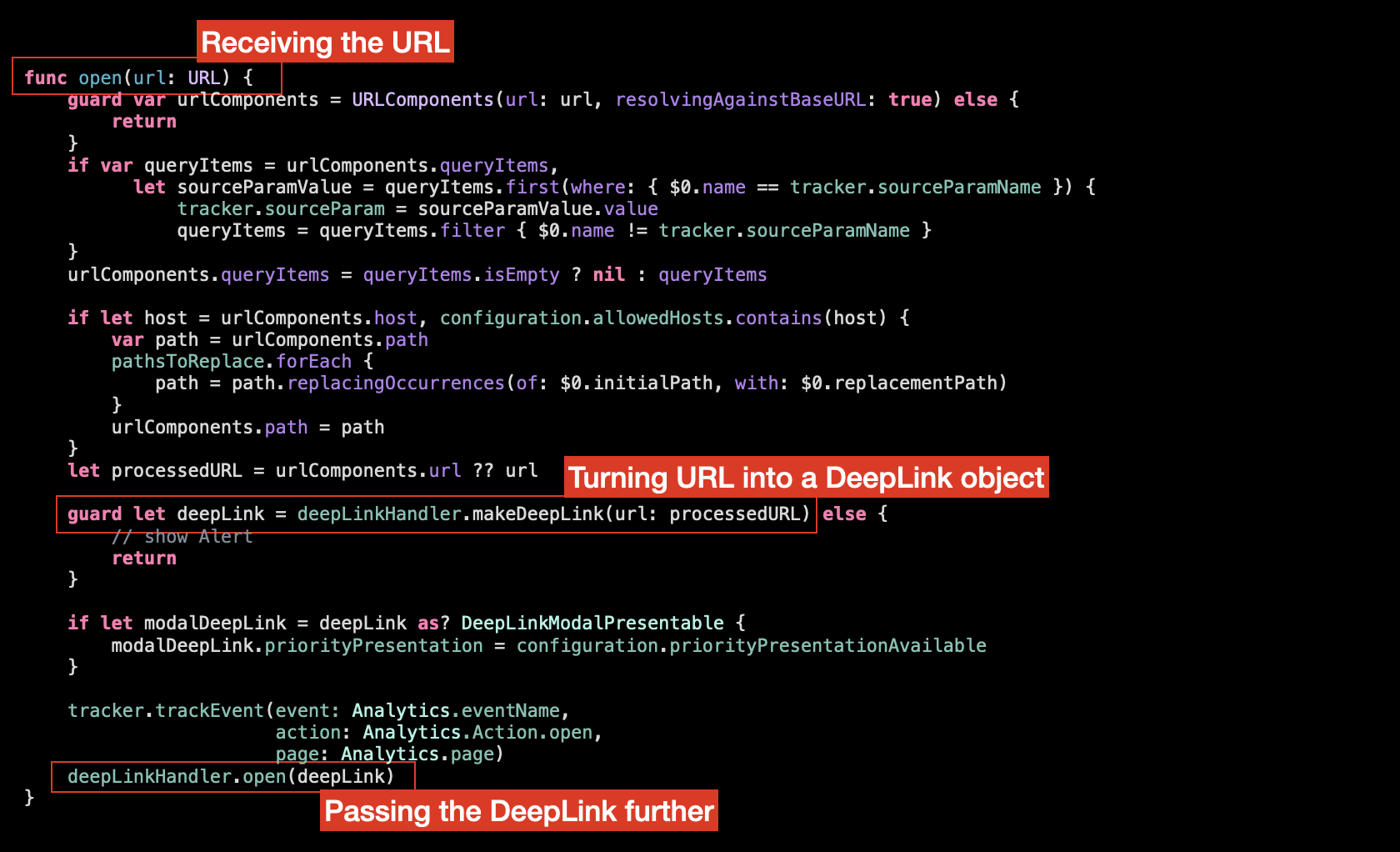
Ideally these high-level operations should be the only things we see inside the function on this level of abstraction. The rest of the logic should be removed into the subfunctions. Let’s check then what is this logic in-between the high-level manipulation:

The first part: Manipulating the URL components we can directly move to a subfunction:
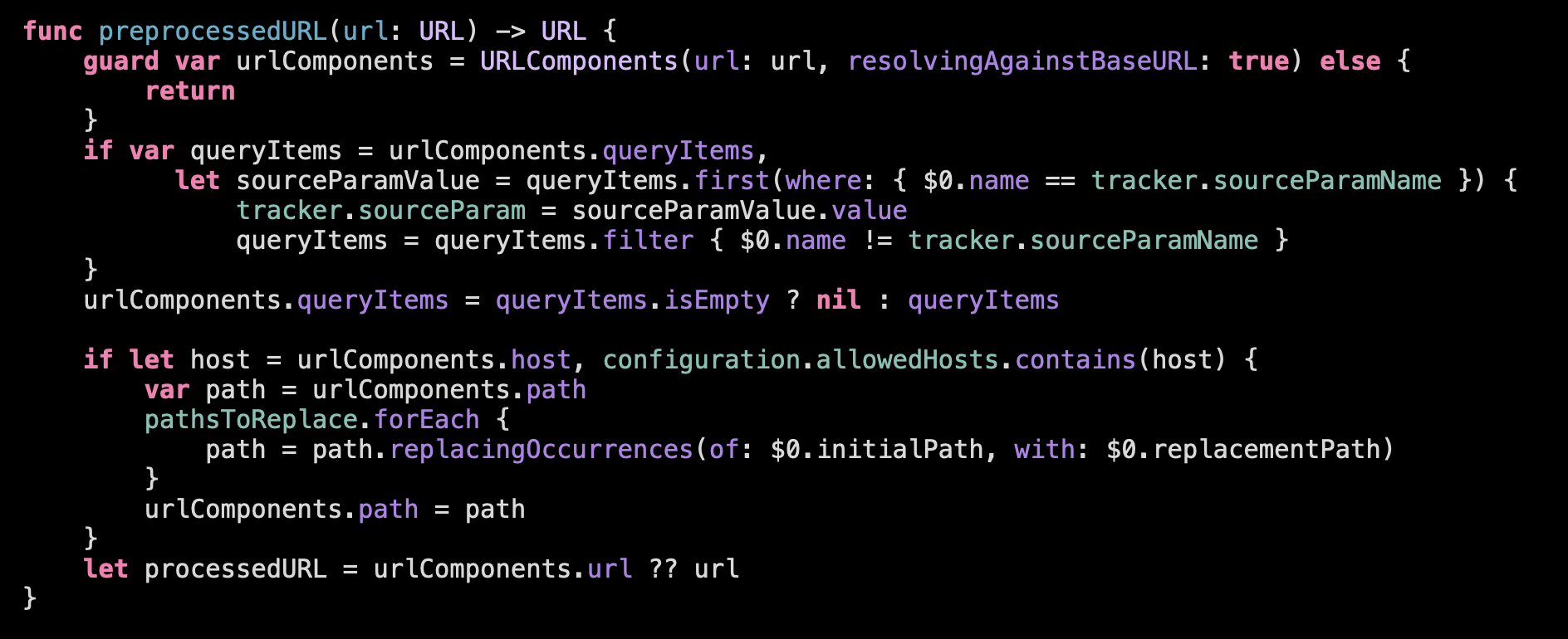
What are the exact operations we are doing here:
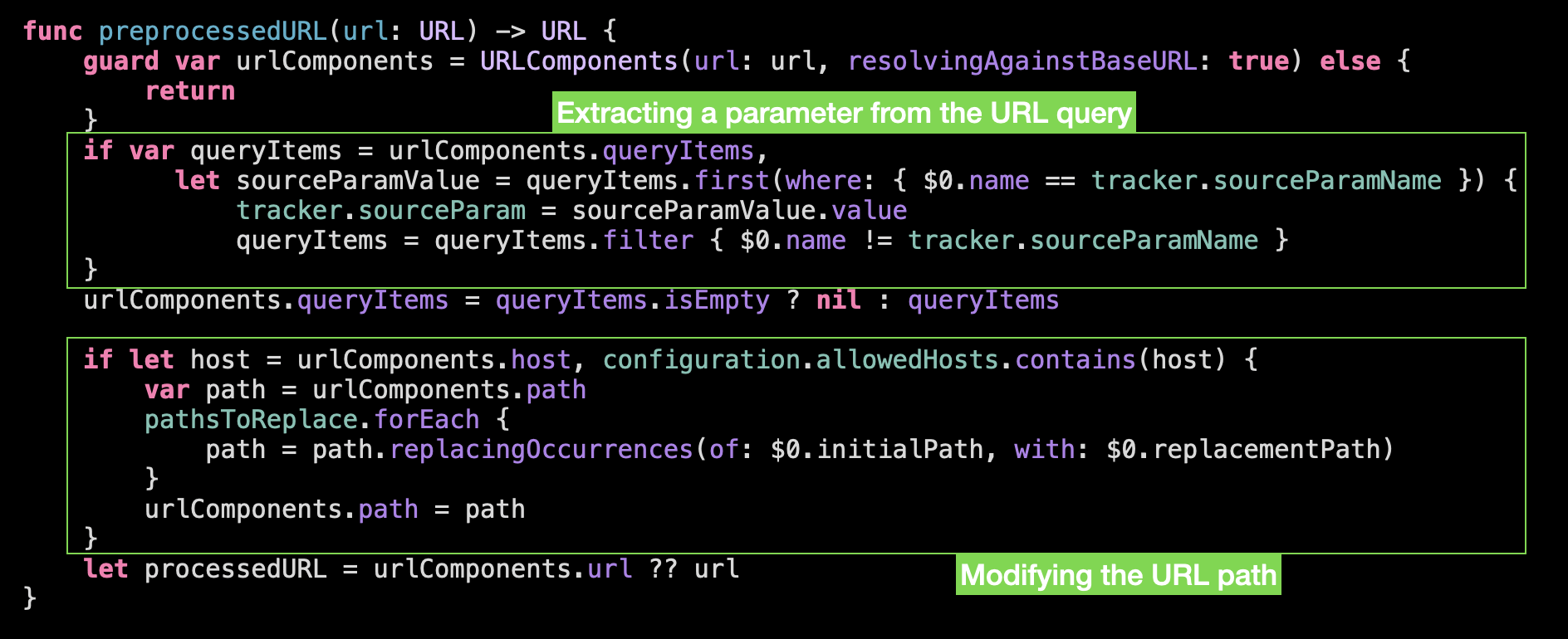
Should we move these two operations to the next abstraction level and separate them into the subfunctions? Probably… But before doing this let’s check the object of manipulation within the fucntion:
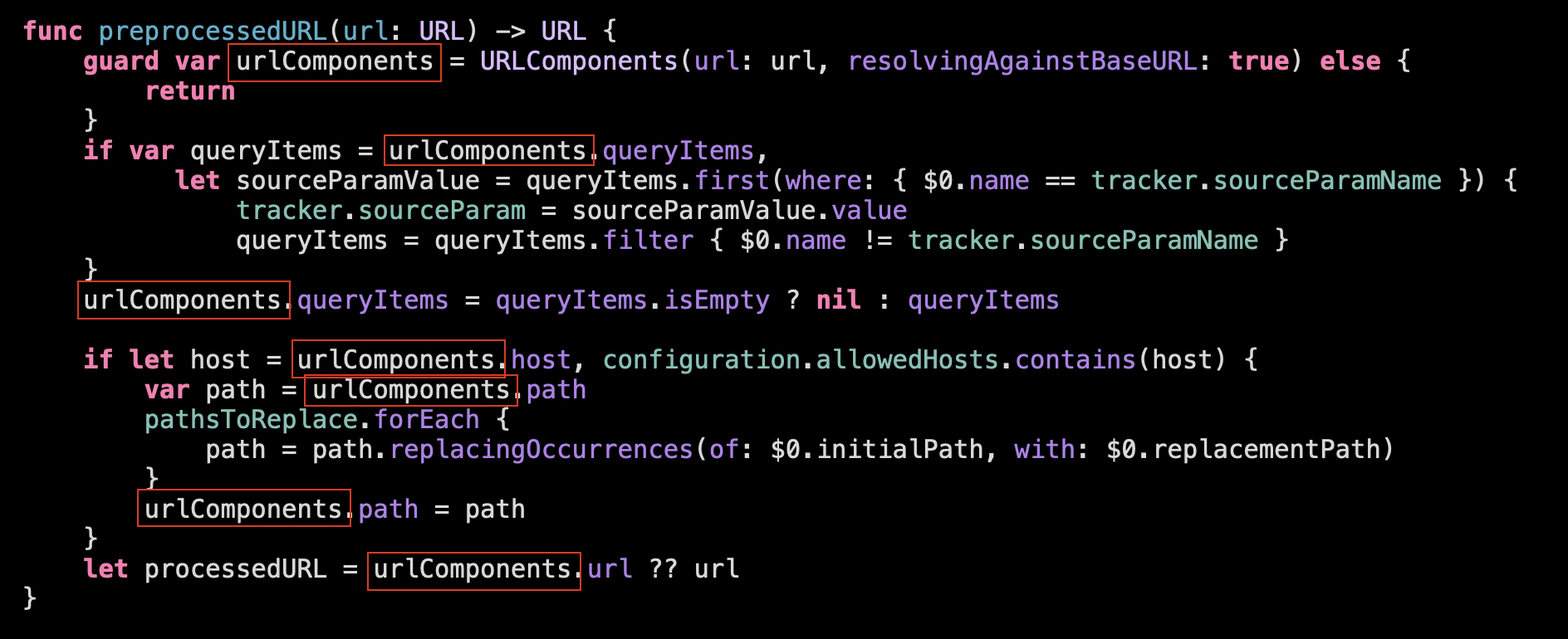
Even though we work with the query, path and host, technically, URLComponents is a shared state for these different operations. We manipulate the same object on the same level of abstraction, so if we split the function we will need to path the data in and out, that will complicate the understanding.
So we are leaving this preprocessedURL()-function as it is, without splitting it further. It is not tiny, but seems comprehensible enough.
Back to our root-function. We moved the preprocessing logic out. Should we do the same with another non-high-level part?
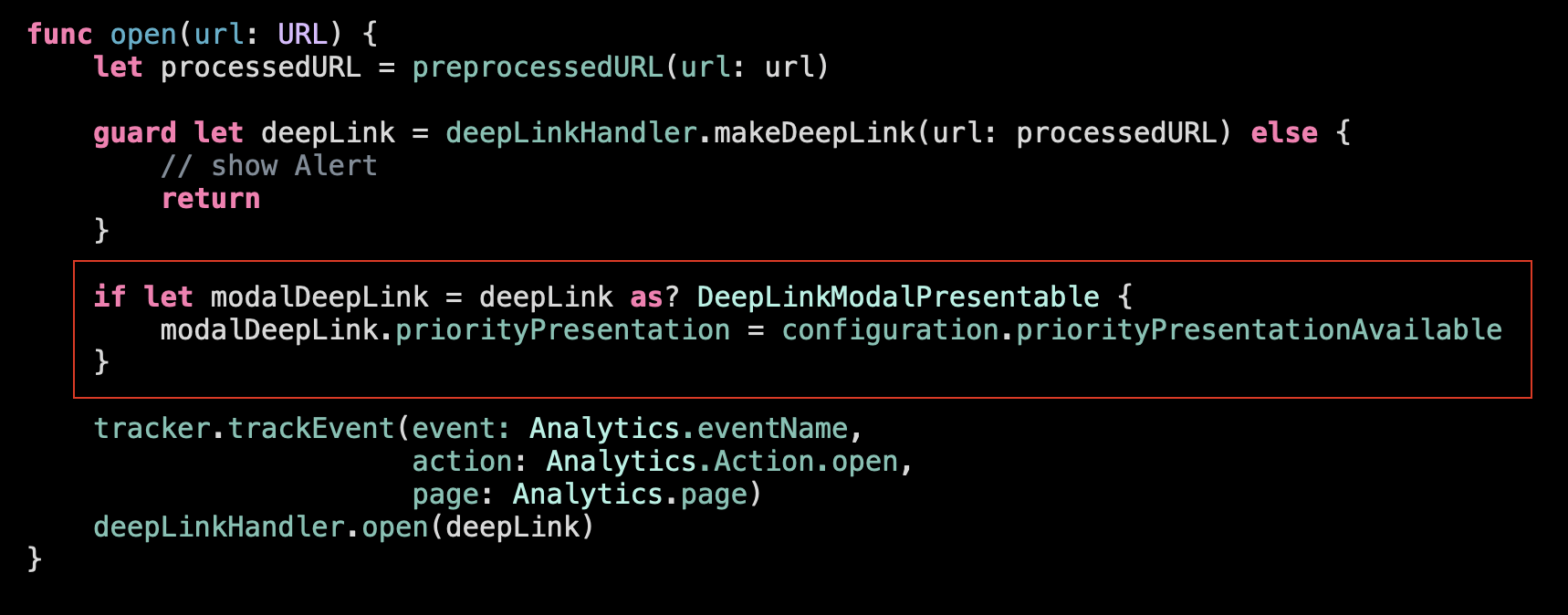
Let’s explore this option…
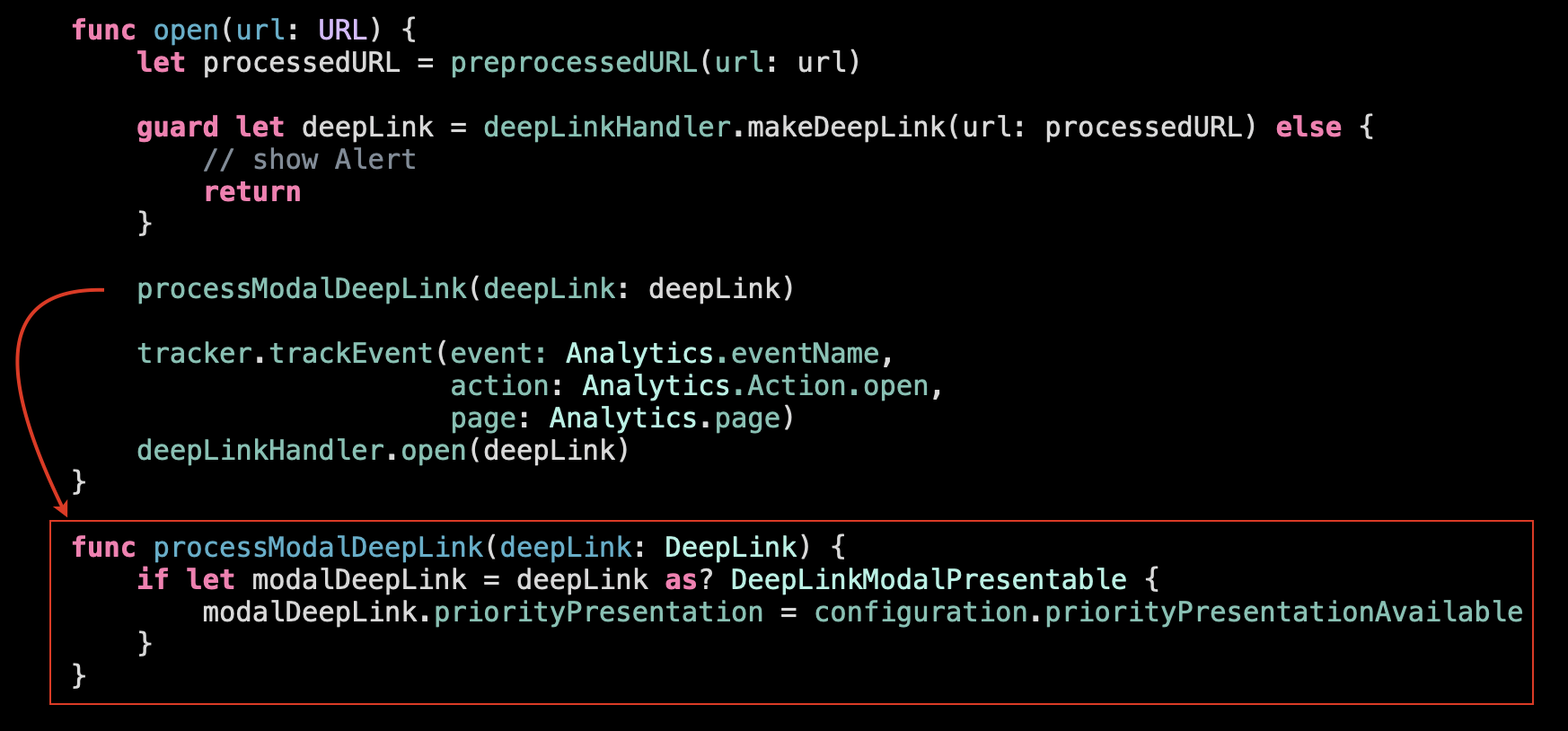
…looks neat.
And the last thing left is this tracking function:
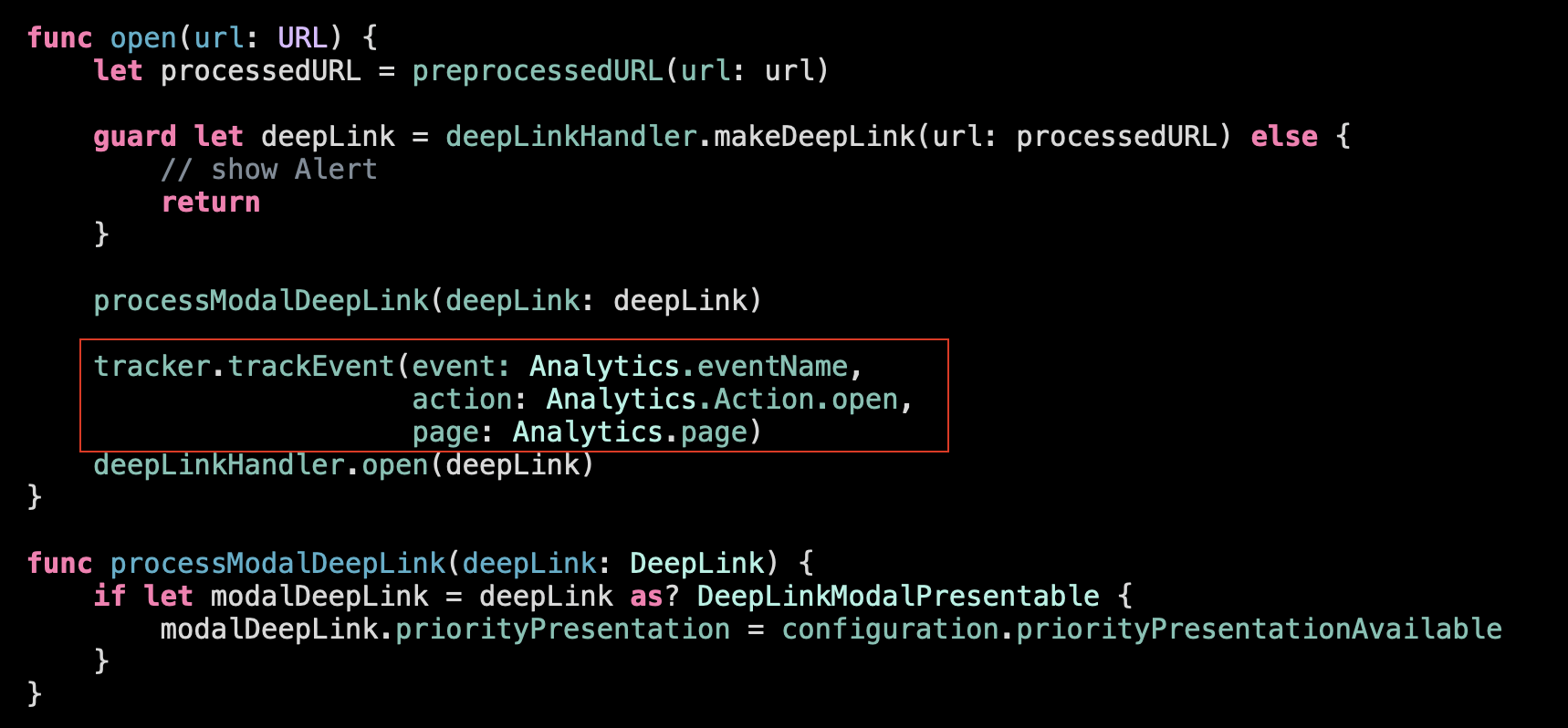
It doesn’t belong to the high-level operations we perform here. Instead it’s a side-effect of opening a deep link. Every time we open a Deep Link we want to track it. So these 2 operations (passing a deep link further to open and tracking it) are related to the same event. So it makes sense to encapsulate this logic and separate it to a subfunction (that can be reused further if a deep link comes from somewhere other than the external URL: push notification, home screen widget or a Siri intent.):
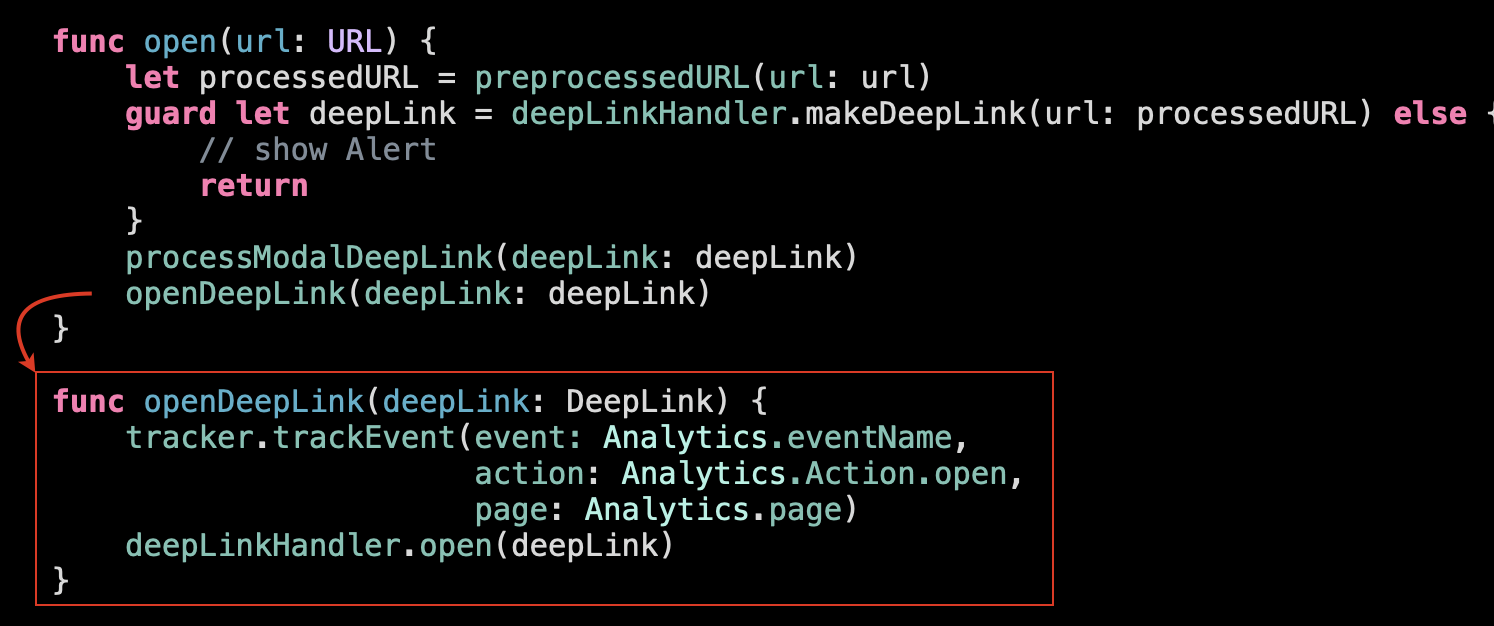
Our root function became much simpler, more straightforward and comprehensible.
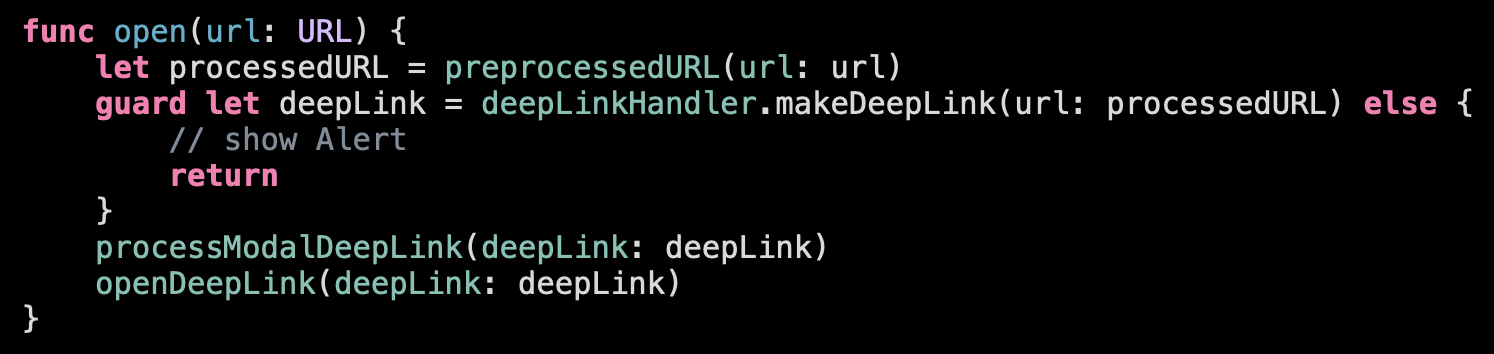
We decomposed it, separated different level of abstractions, considered what belongs to each other and what doesn’t and even thought about some possible future improvements. Now it’s much easier to reason about this logic and if needed get deeper end explore the details.
Conclusion
Thoughtful code and logic distribution is one of the most effective ways to manage complexity in software projects. It shapes how easily developers can understand, navigate, and evolve a system. When structure reflects responsibility, cohesion keeps related pieces close, and visibility is properly constrained, the codebase becomes less like a maze and more like a well-marked map. The clearer the layout, the less mental effort is needed to get things done — and the more confident we can be when making changes. In the long run, it’s not just what the code does that matters, but how it’s organized — because structure is what makes complexity sustainable.