

This is the introduction for the Complexity series - a set of articles where we will explore the causes of complexity in our projects (not only related to the code) and the ways to minimise it. In this piece we will touch upon what exactly complexity is, how can we measure it and why should we care about it at all. In the
The topic is mostly relevant for ones who spend decent amount of work time reading and maintaining existing code. I know there are developers and teams who produce and ship projects without maintaining them afterward. For them the problem is not so relevant I believe.
What is Complexity?
Complexity is not an absolute measure—it exists on a relative scale. One idea, system, or solution is more or less complex compared to another. The key factor that defines this scale is cognitive load—the mental effort required to understand and work with a concept, system, or solution.
When we describe something as “too complex,” we’re often expressing that we can’t comfortably hold all the moving parts in our head at once. This isn’t a failure of intelligence—it’s a reflection of the natural limits of human cognition.
To understand these limits, it helps to know how our brain processes information. This involves three core systems:
- Sensory memory, which quickly absorbs information from our environment (like reading code on a screen or hearing someone explain an algorithm).
- Working memory, the active space where we process, evaluate, and manipulate information.
- Long-term memory, which stores everything we’ve learned and can be retrieved when needed.
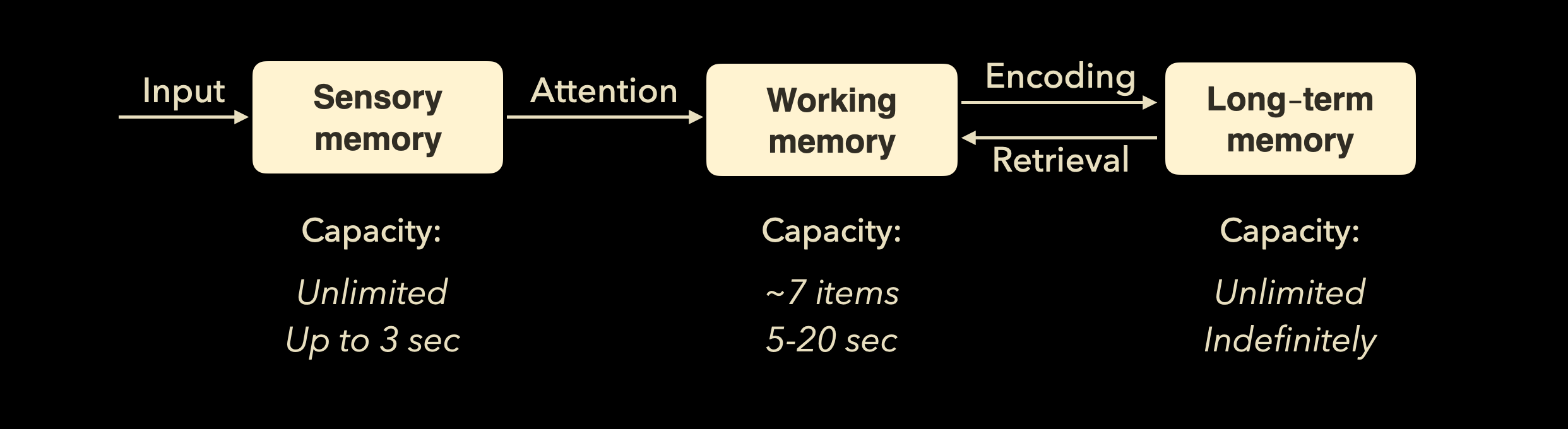
When we solve problems, design systems, or debug code, we’re mostly operating in working memory. It’s where the mental “action” happens.
But here’s the catch: working memory is extremely limited.
According to cognitive science, most people can actively manage only about 5 to 9 chunks of information at a time (a concept famously explored in Miller’s Law, 1956). A “chunk” might be a variable name, a function’s purpose, a dependency between modules, or a user’s intent.
If the code or system we’re working with requires us to hold 15 or 20 different things in mind—branches, side effects, state changes, API constraints—we quickly exceed our cognitive capacity. This is when we start to feel overwhelmed, miss important details, or make mistakes.
Types of complexity
When it comes to human-made systems, there are two types of complexity that are always present in some combination. Some systems are inherently difficult. So difficult that even the interface might look very complex. Take an aircraft cockpit, for example.

There are decades of evolution behind this interface and it is already as easy as it can physically get. We cannot make it simpler without loosing some functionality. This type of complexity is called essential complexity.
In other cases, the system (for instance a device to make coffee) may be implemented differently.

Both of these options bring the same amount of essential complexity. But the second one is much harder to use despite doing the same thing. This extra complexity (of the second approach compared to the first one) is called added or accidental.

What Is Cognitive Load, Really?
Cognitive load comes in three forms:
- Intrinsic load – The inherent complexity of the task itself.
- Extraneous load – The added complexity introduced by poor design, confusing code, or unclear naming.
- Germane load – The effort dedicated to learning, forming mental models, and gaining insight.
Good software design doesn’t aim to eliminate cognitive load — it aims to reduce extraneous load (as we cannot do much with inherent complexity) and support germane load.
That means writing code and building systems that:
- Clearly reflect intent
- Reduce unnecessary nesting or state juggling
- Use consistent patterns and naming
- Separate concerns logically
- …and other things we will discuss in details in the following articles.
In essence: we can’t increase human cognitive capacity, but we can reduce how much of it our code consumes.
Why Does Complexity Matter?
By now, it should be clear: the more complex a system is, the more cognitive capacity it demands — and the harder it becomes to work with. This isn’t just a matter of elegance or personal preference; it affects the very foundations of how we build, scale, and sustain software.
In software engineering, excessive cognitive load has a major impact:
-
Complex systems are harder to understand, debug, modify, and maintain. Every added layer of logic or abstraction increases the mental effort required to trace behavior and reason about change. This slows down development and makes even small changes risky.
-
The more time new developers spend grasping the codebase, the longer it takes for them to contribute. Onboarding becomes a bottleneck when the mental model of the system is hard to build. Instead of learning the business logic, newcomers spend their energy deciphering internal complexity.
-
Scaling is easier with simpler systems. Simple, modular designs can be extended with minimal side effects. In contrast, complex systems resist change—every addition feels like a Jenga move that could topple the whole thing.
-
Complex relationships between parts and hidden dependencies lead to unpredictable side effects and bugs. When components are tightly coupled or behavior is implicit, it’s easy to break one thing while changing another. These bugs are often subtle, hard to detect, and expensive to fix.
-
Decision-making is slower when we don’t fully understand the system. Whether it’s choosing where to place new code or deciding how to fix a bug, unclear systems create hesitation. Developers are more likely to delay action, over-engineer solutions, or second-guess themselves.
-
Communication speed depends on complexity. Complex systems require complex explanations, which leads to more meetings, more documentation, and more back-and-forth. Teams must spend more time in discussions; developers need to explain more to their non-technical colleagues. This communication overhead reduces focus time and slows down collaboration.
-
Worse developers’ well-being. Cognitive overload is one of the leading causes of frustration and burnout. Developers feel drained from the difficulty of the problems as well as from the difficulty of the tools and systems they’re forced to work with. Instead of engaging in creative problem-solving, they’re stuck untangling complexity.
That’s why we should care deeply about complexity—and strive to minimize the cognitive load of our solutions. Clear, maintainable systems don’t just improve productivity; they make the work more humane, sustainable, and rewarding.
Measuring complexity.
How can we measure something as abstract as complexity?
Even in the early days of programming, developers sought ways to do it.
1. Lines of code
Counting lines of code is the simplest and oldest approach. It gives a rough sense of the size of a codebase or function. While more lines often correlate with greater complexity, it doesn’t capture how those lines behave—100 lines of well-structured logic may be easier to work with than 20 lines of tangled conditions. Still, this metric is useful for quick comparisons or spotting bloated methods.
2. Cyclomatic Complexity
In the 1970s, a more refined metric emerged: Cyclomatic Complexity—which counts the number of independent paths through a block of code. Each conditional or loop adds a new decision path, increasing the effort required to test, understand, and reason about the code.
For example, this simple function has only one possible path, so its complexity is 1:
func doSomething(x: Int) -> Int {
let y = x + 10
return y
}
Introduce a conditional statement, and it jumps to 2:
func doSomething(x: Int) -> Int {
let y = x + 10
if y > 0 {
return y
} else {
return 0
}
}
Loops and additional conditionals further increase complexity, requiring more unit tests and increasing the chance of bugs hiding in untested paths.
3. Halstead Volume
The Halstead Volume metric calculates complexity based on the number of operators and operands in the code. It aims to reflect the mental effort required to understand the code’s structure, not just its control flow. The more unique elements and the more frequently they’re used, the higher the volume—and the higher the cognitive load. It’s especially useful in analyzing how dense or abstract code is, even if the flow is relatively linear.
4. Maximum Nesting Level
This metric tracks how deeply control structures (like if, for, while, etc.) are nested within each other. High nesting levels often signal increased cognitive load, as the reader must keep track of multiple levels of logic simultaneously. Deep nesting also makes it harder to isolate bugs, refactor code, or trace execution paths. Flattening nested logic typically improves readability and testability.
5. Number of Parameters
The more parameters a function takes, the more information the developer must supply and keep in mind. Large parameter lists often indicate a lack of clear abstraction or an overloaded responsibility. Ideally, functions should take only the data they truly need—grouping related values into structs or objects where appropriate. Fewer parameters usually mean simpler, more focused code.
6. Maintainability Index
The Maintainability Index combines multiple metrics — Lines of Code, Cyclomatic Complexity, and Halstead Volume — into a single score from 0 to 100. A higher score suggests that the code is easier to maintain, while lower scores indicate more technical debt and higher risk. It’s useful as a broad health check across a codebase, though it should always be interpreted in context.
MI = MAX(0,(171 -
5.2 * ln(Halstead Volume) -
0.23 * (Cyclomatic Complexity) -
16.2 * ln(Lines of Code)) *
100 / 171)
A function may pass this metric numerically but still be hard to understand due to naming, coupling, or domain complexity — so always pair it with qualitative judgment.
Some metrics focus on data structures and object-oriented design:
7. Cohesion
Cohesion measures how closely related a class or module’s internal responsibilities are. High cohesion means the parts work together toward a single purpose, making the code easier to understand and reuse. Low cohesion suggests the class is doing too much—or things that don’t logically belong together—indicating a candidate for refactoring. High cohesion leads to better modularity and lower cognitive load.
One common metric is LCOM (Lack of Cohesion of Methods), which analyzes how many methods in a class access the same fields. If most methods operate on distinct sets of fields, cohesion is low. If they operate on shared fields, cohesion is high.
8. Coupling
Coupling is the degree of interdependence between modules or components. Tight coupling means changes in one module often require changes in others, making the system harder to evolve. Loose (or low) coupling allows components to be developed, tested, and reused independently. Reducing coupling makes codebases more flexible and maintainable in the long run.
To measure it count the number of external classes or modules a given class references (via field types, method parameters, return types, method calls). A popular metric is CBO (Coupling Between Objects).
9. Depth of Inheritance Tree (DIT)
This metric indicates how many levels a class is from the root of the hierarchy. Deeper trees can make it harder to trace behavior, especially if multiple layers override the same methods. While inheritance can promote reuse, overusing it leads to fragile designs and unexpected interactions. Favoring composition over inheritance often reduces complexity here.
To measure it simply count the number of levels from the class to the root of the inheritance hierarchy.
E.g., if ViewController → BaseController → UIViewController, then DIT = 2.
10. Response for a Class (RFC)
Response for a Class measures the number of different methods that can be invoked in response to a message sent to an object. A high RFC suggests the class has many responsibilities or exposes too much internal behavior. This can overwhelm the reader and create tight coupling between the class and its clients. Lower RFC typically implies a cleaner, more focused interface.
To measure it count the class’s own methods and any other methods they call (including internal and external calls).
RFC = Number of methods defined in the class + number of methods those methods invoke
11. Number of Own Methods
This metric counts how many methods are defined directly in the class. While not all methods are created equal, a high number can indicate that the class has too many responsibilities or behaviors. Keeping classes small and focused — ideally centered around a single responsibility — reduces the burden on readers and improves reusability.
To measure it count all the methods defined in the class file itself, excluding inherited ones. This includes instance methods, class methods, and private/internal methods. A high count often signals a violation of the Single Responsibility Principle
12. Number of Overridden Methods
Tracking overridden methods helps identify cases where subclass behavior diverges from its parent. A high number may suggest that the base class isn’t providing a stable abstraction or that inheritance is being misused. When overriding becomes the norm rather than the exception, it’s often a sign that composition would be a better fit.
Count methods in the class that explicitly use the override keyword (in Swift or Java), or that match inherited method signatures. High counts may indicate unstable inheritance hierarchies or improper use of inheritance instead of composition.
13. Number of Implemented Interfaces (NOII)
This measures how many interfaces a class implements. While implementing interfaces supports flexibility and polymorphism, too many interfaces can dilute a class’s identity and increase its obligations. Excessive interface usage may lead to complex dependency graphs and make the class harder to test, understand, or change.
Why to bother measuring?
All these metrics are based on static code analysis. That’s what the tools like SonarQube, Checkmarx, and SwiftLint use to assess code quality. Complexity in software development extends far beyond the code itself—we’ll explore that later. Still, poorly implemented abstract concepts will eventually lead to complex code, which we can measure using these techniques.

There are arguments regarding the origin of this idea, but it doesn’t really matter. Measuring doesn’t necessarily mean controlling, but it’s the first step toward it.
That was it for now, to be continued…